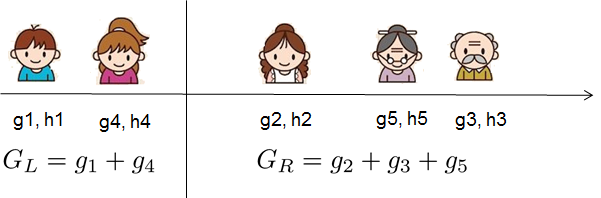A salient characteristic of objective functions is that they consist two parts: training loss and regularization term:
obj(θ)=L(θ)+Ω(θ)
where L is the training loss function, and Ω is the regularization term. The training loss measures how predictive our model is with respect to the training data. A common choice of L is the mean squared error, which is given by
L(θ)=i∑(yi−y^i)2
Another commonly used loss function is logistic loss (log-likelihood), to be used for logistic regression:
L(θ)=i∑[yiln(1+e−y^i)+(1−yi)ln(1+ey^i)]
The regularization term is what people usually forget to add. The regularization term controls the complexity of the model, which helps us to avoid overfitting.
Tree Model with num_iteration K :where K is the number of trees, f is a function in the functional space
The form of MSE is friendly, with a first order term (usually called the residual) and a quadratic term. For other losses of interest (for example, logistic loss), it is not so easy to get such a nice form. So in the general case, we take the Taylor expansion of the loss function up to the second order:
Here w is the vector of scores on leaves, q is a function assigning each data point to the corresponding leaf, and T is the number of leaves. In XGBoost, we define the complexity as tuned by gamma and lambda:
where Ij={i∣q(xi)=j} is the set of indices of data points assigned to the j-th leaf. Notice that in the second line we have changed the index of the summation because all the data points on the same leaf get the same score. And the form [Gjwj+21(Hj+λ)wj2] is quadratic.
The optimal value is now induced as
Specifically we try to split a leaf into two leaves, and the score it gains is
Gain =21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
1) the score on the new left leaf
2) the score on the new right leaf
3) The score on the original leaf
4) regularization on the additional leaf.
5) We can see an important fact here: if the gain is smaller than γ, we would do better not to add that branch.
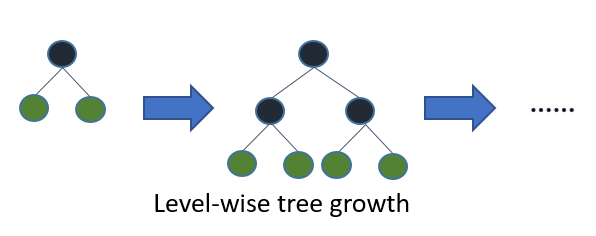
XGBoost 采用 level (depth)-wise 的增长策略,该策略遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型complexity,不容易overfitting。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
like the following image: